英伟达发布超长上下文推理芯片Rubin CPX 算力效率拉爆当前旗舰
小米11 Ultra是年度旗舰,会在新品发布会上发布。 #生活知识# #科技生活# #科技新品发布#
财联社9月10日讯(编辑 史正丞)全球人工智能算力芯片龙头英伟达周二宣布,推出专为长上下文工作负载设计的专用GPU Rubin CPX,用于翻倍提升当前AI推理运算的工作效率,特别是编程、视频生成等需要超长上下文窗口的应用。
英伟达CEO黄仁勋表示,CPX是首款专为需要一次性处理大量知识(数百万级别tokens),并进行人工智能推理的模型而构建的芯片。
需要说明的是,Rubin就是英伟达将在明年发售的下一代顶级算力芯片,所以基于Rubin的CPX预计也要到2026年底出货。下一代英伟达旗舰AI服务器的全称叫做NVIDIA Vera Rubin NVL144 CPX——集成36个Vera CPU、144块Rubin GPU和144块Rubin CPX GPU。

(NVIDIA Vera Rubin NVL144 CPX机架与托盘,来源:公司博客)
英伟达透露,搭载Rubin CPX的Rubin机架在处理大上下文窗口时的性能,能比当前旗舰机架GB300 NVL72高出最多6.5倍。
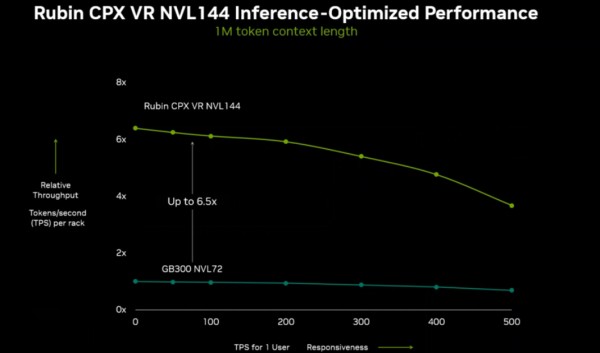
据悉,下一代旗舰机架将提供8 exaFLOPs的NVFP4算力,比GB300 NVL72高出7.5倍。同时单个机架就能提供100TB的高速内存和1.7PB/s的内存带宽。
言归正传,英伟达之所以要在Rubin GPU边上再配一块Rubin CPX GPU,自然是为了显著提升数据中心的算力效率——用户购买英伟达的芯片将能赚到更多的钱。英伟达表示,部署价值1亿美元的新芯片,将能为客户带来50亿美元的收入。
为何需要两个GPU?
作为行业首创之举,英伟达的新品在硬件层面上分拆了人工智能推理的计算负载。
英伟达介绍称,推理过程包括两个截然不同的阶段:上下文阶段与生成阶段,两者对基础设施的要求本质上完全不同。
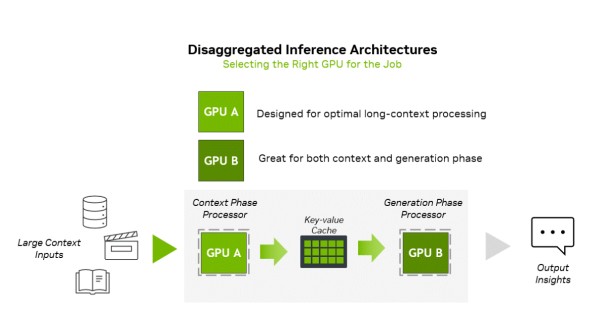
上下文阶段属于计算受限(compute-bound),需要高吞吐量的处理能力来摄取并分析大量输入数据,从而生成首个输出token。相反,生成阶段则属于内存带宽受限(memory bandwidth-bound),依赖高速的内存传输和高带宽互联(如 NVLink),以维持逐个token的输出性能。
当前顶级的GPU都是为了内存和网络限制的生成阶段设计,配备昂贵的HBM内存,然而在解码阶段并不需要这些内存。因此,通过分离式处理这两个阶段,并针对性地优化计算与内存资源,将显著提升算力的利用率。
据悉,Rubin CPX专门针对“数百万tokens”级别的长上下文性能进行优化,具备30petaFLOPs的NVFP4算力、128GB GDDR7内存。
英伟达估计,大约有20%的AI应用会“坐等”首个token出现。例如解码10万行代码可能需要5-10分钟。而多帧、多秒的视频,预处理和逐帧嵌入会迅速增加延迟,这也是为什么当前的视频大模型通常仅用于制作短片。
英伟达计划以两种形式提供Rubin CPX,一种是与Vera Rubin装在同一个托盘上。对于已经下单NVL144的用户,英伟达也会单独出售一整个机架的CPX芯片,数量正好匹配Rubin机架。


海量资讯、精准解读,尽在新浪财经APP
网址:英伟达发布超长上下文推理芯片Rubin CPX 算力效率拉爆当前旗舰 https://zlqsh.com/news/view/60800
相关内容
S妈那边开始发力了,20小时前,王伟忠公司旗下的账号…特写:布达拉宫“香布”换新迎藏历新年
DeepSeek火爆全网,OpenAI首席执行官发声
《哪吒2》在港上映,场面火爆超预期
英国电影学院奖获奖名单公布 《沙丘2》获两项大奖
展示武力?英媒公布画面:英首相“罕见”视察绝密核潜艇,“似乎是向莫斯科发出信号”
原创布达拉宫的厕所为何300年不清理还能用?不得不佩服古人的智慧
英皇爆雷:谢霆锋、容祖儿、李克勤、TWINS等恐受影响
《射雕英雄传》业内看片,肖战演技获赞:春节档三大赢家之一
旺仔小乔已掉粉超400万 道歉信查重率被疑高达97%
随便看看
最新生活
- 一恋爱我会撒娇又耍赖
- 刘宇宁这一定是真实反应,谁看见恐龙不吓一跳啊 刘宇宁|书卷一梦|壮汉
- 孟庭辉落榜,却发现第一名考卷是自己的!她不想就此认命!
- 亮神笑了~好开心好温暖一幕
- 天打雷劈的苦瓜叔嫂长大了一个比一个狠《蜀锦人家》谭松韵郑业成经超
- “爱变脸的小姐姐一枚呀”闺蜜仗义这一块
- 孟庭辉英寡树下一眼定情,闺蜜护友棒打英寡!吴谨言陈哲远
- 妹妹剜心救男人 姐姐剜心救妹妹《沉香如屑》杨紫成毅张睿朱泳腾孟子义
- 又宠又无奈的宁宁 太可爱了
- 老高为了前途 竟让李峋给渣男道歉
热点生活
- 2772
- 2740
- 2719
- 2588
- 2453
- 2045
- 1934
- 1890
- 1707
- 1651

